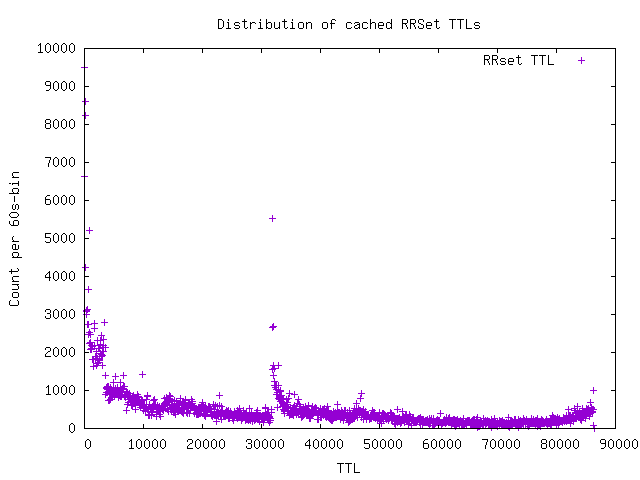
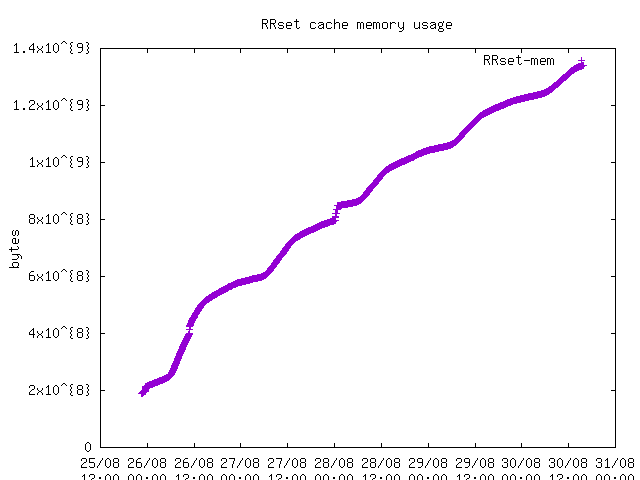
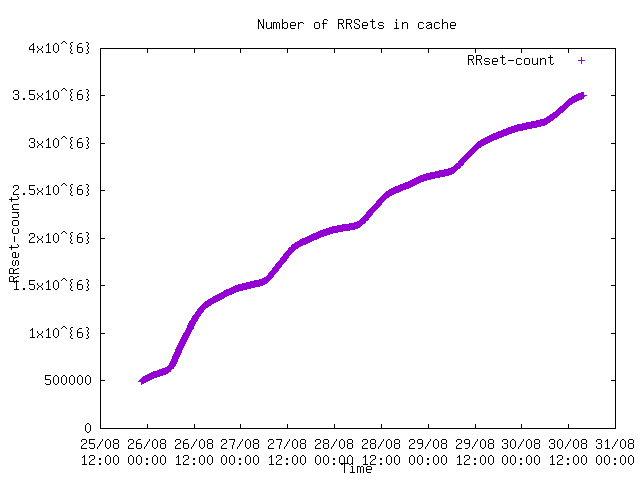
Hi,
I've been running a set of recursive resolvers using both BIND and
unbound for quite a while. This was set up at a time when BIND
supported neither DNS-over-TLS nor DNS-over-HTTPS, so I had set up
unbound to serve those protocols, and from unbound forwarded all the
queries to the BIND instance via
server:
# Must allow query localhost since we use separate instances:
do-not-query-localhost: no
# Forward all queries to local recursor
forward-zone:
name: "."
forward-addr: 127.0.0.1
# Use the forwarders cache, don't build own cache
forward-no-cache: yes
One would have thought that "forward-no-cache" would do what it
claims to do, i.e. to not build a cache, and cause unbound to not
balloon in size. That appears to not be the case, unbound still
grew in both virtual and resident size according to "top", but while
the query volume was low to moderate it didn't really matter all
that much.
However, I recently came across RFC 9462, "Discovery of Designated
Resolvers" where a plain recursive resolver can be set up to serve
"resolver.arpa", and via the "_dns" label and SVCB records on that
node indicate to recursive resolver clients where they can find
endpoints for DNS-over-TLS or DNS-over-HTTPS.
As a consequence of setting this up, on the busiest node in our
setup, the DoT query volume on the unbound side increased around
tenfold, and DoH picked up from around zero to around the same
level, up to around 500qps for each of DoT and DoH.
Unbound was running with default (unconfigured) sizing, and at one
point both unbound and BIND were killed by the kernel for exhausting
swap space (and real memory), both at 32GB. Obviously this is "out
of control". So I tried to configure some basic limits on a few of
the most important data structures in unbound via
# Put some limits on virtual memory consumption
# to avoid being killed due to "out of swap"...
rrset-cache-size: 8G
msg-cache-size: 4G
key-cache-size: 800m
The strange thing is that these limits are not observable as
being obeyed -- "top" currently reports:
PID USERNAME PRI NICE SIZE RES STATE TIME WCPU CPU COMMAND
27045 unbound 25 0 156G 15G CPU/1 23.6H 689% 689% unbound
The virtual size is obviously "over-committed" with respect to
what's actually available (32GB RAM and 32GB swap), possibly via
mmap-based memory allocation(?), and one can *maybe* see it adhering
to the configured limits with respect to the resident set size(?)
However, currently 25GB of swap is already used (the OS is not doing
excessive paging, though), though in the time it's taken to write
this message, swap usage has expanded to 29GB, and it's on its way
to being killed again. The elevated CPU time consumption for
unbound is also a bit suspicious; that appears to have started
around 3-4 hours ago, while unbound was upgraded to 1.20.0 (from
1.19.1) and restarted around midnight, now more than ten hours ago.
(I have system monitoring via collectd.)
Meanwhile, the BIND instance which sees all the queries and
builds its own cache sits at
PID USERNAME PRI NICE SIZE RES STATE TIME WCPU CPU COMMAND
12487 named 85 0 894M 405M kqueue/9 411:21 37.40% 37.40% named
i.e. in the sub-1GB virtual + resident size.
This is all on NetBSD/amd64 9.3.
Obviously the unbound resource consumption is "out of control",
and the configured resource limits appear to do little to nothing
with the virtual memory consumption. I find this concerning.
Ideally I would have liked to bring unbound's virtual memory
consumption in under administrative control. Is that at all
possible?
Or is this simply a memory leak related to either of DoT or DoH?
Guidance sought.
Best regards,
- Håvard