Hi Wouter,
Signed PGP part
Hi Kabindra,
I have not heard of this before, how is TCP affecting NSD?
After couple thousand of TCP queries, NSD goes unresponsive for both TCP and UDP.
[kabindra@1 ~]$ dig @hostname -p 5350 ch txt hostname.bind
; <<>> DiG 9.8.1 <<>> @ -p 5350 ch txt hostname.bind
; (2 servers found)
;; global options: +cmd
;; connection timed out; no servers could be reached
[kabindra@1 ~]$ dig @hostname -p 5350 ch txt hostname.bind +tcp
; <<>> DiG 9.8.1 <<>> @ -p 5350 ch txt hostname.bind +tcp
; (2 servers found)
;; global options: +cmd
;; connection timed out; no servers could be reached
One thing we noticed, we have set the server-count to 4, so it should have 4 child process forked, right? when NSD goes unresponsive, we see couple of process and more than 4 child processes.
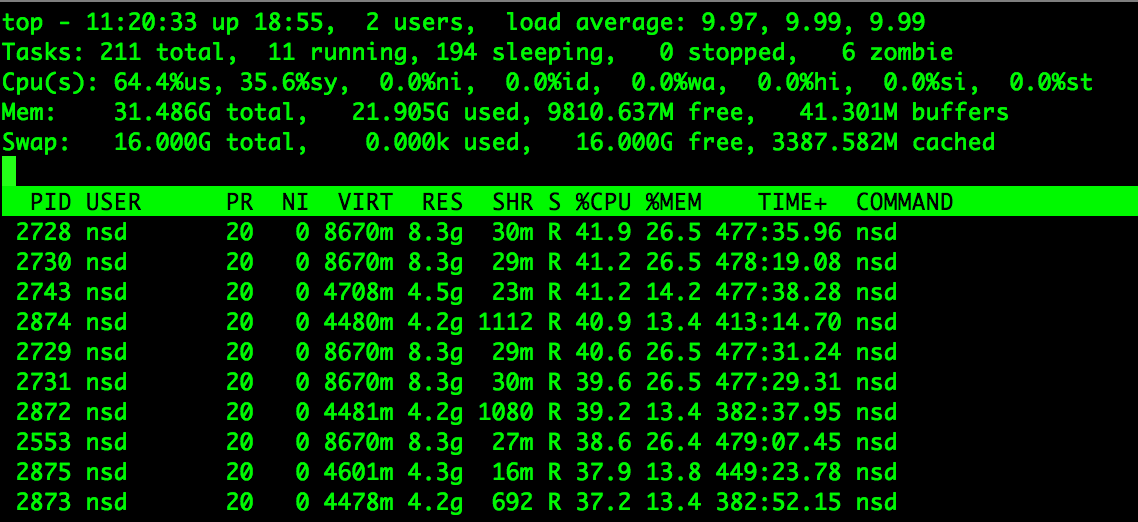
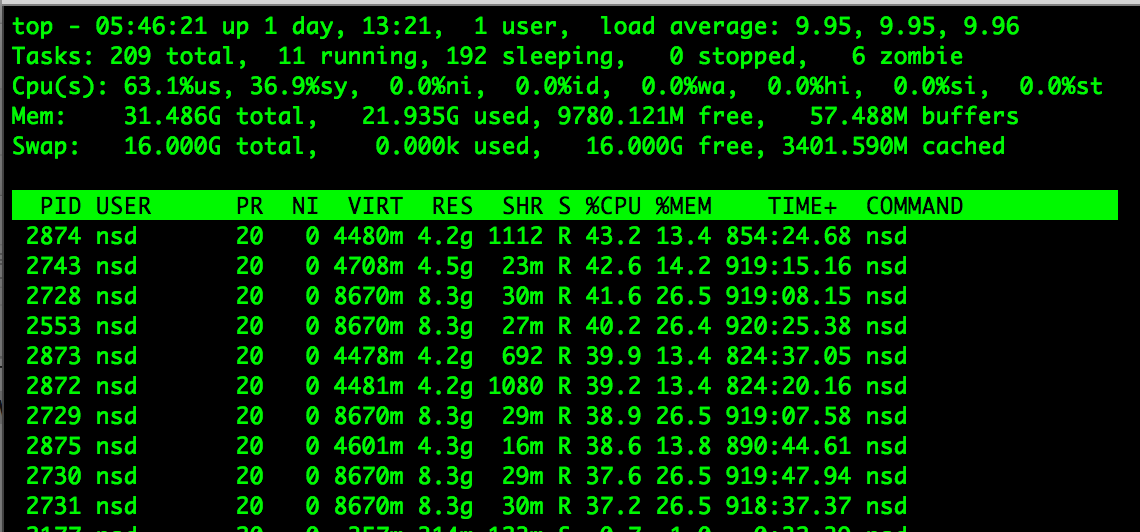
also, these NSD processes are using lots of CPU. I have left this box out of service for almost 2 days now after going unresponsive but you can see the cpu usage on the below image, it’s not coming down.
NSD has a
fixed number of tcp connections, configured in tcp-count: 100 from the
nsd.conf file. That should be what is services. You should increase
that count to increase responsiveness to TCP.
Yes, that’s what we changed earlier to increase responsiveness to TCP.
UDP should be unaffected.
That is not the case we are seeing.
The backlog is for tcp connections waiting to be accepted. 256 is
reasonably portable, reasonably large. I don’t see how that value is
your problem.
It has been so far and should be true for most of the users but recently with the increase in TCP traffic, I doubt that’s still the case. With the RRL implemented I believe it’s going to increase some amount of TCP traffic than what it used to be, right?
So say if I increase the number of tcp-counts to 1024 but my backlog is set to 256, will I still be able to get 1024 connections at a time or will I be limited to 256 connections concurrently?
Is your kernel and networking subsystem failing?
I don’t think so, if it was the problem I would see problem for other services on that server as well, right?
The OS can return EMFILE or ENFILE to accept(), nsd starts to stop
accepting TCP connections to relieve buffer stress on the OS. But
again, UDP should not have been impacted?
Again, that’s not the case we are seeing.
Are you using so-reuseport: yes?
Nope.
I have had reports that it disrupts
connectivity (depending on OS, particular version of the OS, and more
recent versions of NSD do not use reuseport on TCP anymore).
Sorry, forgot to mention earlier, we are on CentOS 6 and NSD 4.1.8.
Thanks.
Best regards, Wouter
Hi,
We are seeing some large number of TCP connections to our DNS
servers (in thousands) and NSD goes unresponsive after certain time
and doesn’t recover, it stops responding to UDP as well. We tried
increasing the number of tcp-counts but it doesn’t help. I noticed
the TCP backlog is hardcoded to 256 in NSD config, so even with
customised TCP backlogs on the system its still being throttled at
around 256. Is there anyway we can change this value without
recompiling the NSD.
[kabindra@05 nsd-4.1.8]$ grep BACKLOG * config.h.in:#undef
TCP_BACKLOG configure:#define TCP_BACKLOG 256
configure.ac:AC_DEFINE_UNQUOTED([TCP_BACKLOG], [256], [Define to
the backlog to be used with listen.])
We are using NSD4.1.8.
( From one of the servers that went unresponsive, we have seen that
TCP number closing to 10k. )
#ss -s Total: 5591 (kernel 5640) TCP: 5067 (estab 4968, closed 4,
orphaned 0, synrecv 0, timewait 3/0), ports 28
Transport Total IP IPv6 * 5640 - - RAW
0 0 0 UDP 122 63 59 TCP 5063
5017 46 INET 5185 5080 105 FRAG 0 0
0
Thanks.
Regards, Kabindra Shrestha
_______________________________________________ nsd-users mailing
list nsd-users@NLnetLabs.nl
https://open.nlnetlabs.nl/mailman/listinfo/nsd-users
nsd-users mailing list
nsd-users@NLnetLabs.nl
https://open.nlnetlabs.nl/mailman/listinfo/nsd-users
Regards,
Kabindra Shrestha