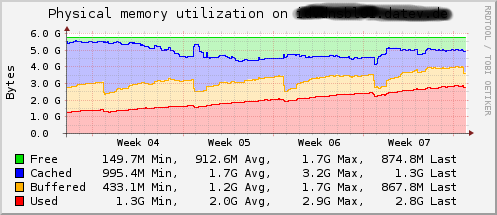
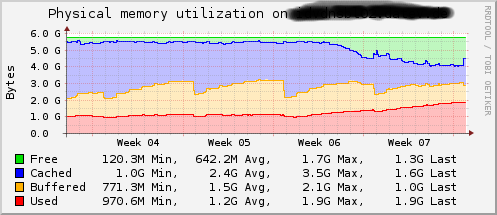
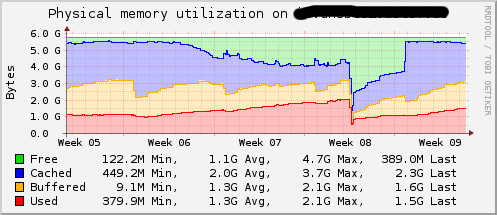
I found my two of my name servers are consuming more and more memory over time.
NSD is supervised and started by "/usr/sbin/nsd -c /var/lib/nsd/etc/nsd/nsd.conf -d"
I have remote-control and chroot enabled. The server handle only one zone.
Zone data updates are "pushed" by a bind master more then 1000 times per day (it's a dnsbl zone)
There is also a rbldnsd on the same host but I assume it's unrelated to the problem.
* nsd-4.0.0.png shows the problem on server #1
* nsd-4.0.1.png shows my tests on server #2:
In week 3,4 and 5 it was a nsd-4.0.0. A daily cronjob called "killall nsd".
(NSD is restarted by the supervisor every time)
In week 6 I updated to nsd-4.0.1 and stopped the daily "killall nsd"
I think there is a little amount of memory not released somewhere in NSD.
But I have no idea how to find the memory leak.
I have been tracing what appears to be the same issue on my end for a month or two (NSD 4.0.1 on a 64bit Ubuntu Linux 12.04 machine). I have built a test harness that reloads a single one-record-zone as fast as it can, capturing the memory utility, memory maps, etc of the parent and xfrd processes coupled with system slab allocator statistics.I have seen large multipliers in RAM utilization of the parent process between where it started and where it was at the latest sample. Another problem is that the time a reload takes skyrockets. I can observe the reload time taking 40x or more time than when the daemon freshly started. I am also restarting servers periodically – which fixes both the memory consumption and the reload time issues.
In my testing, I see that the memory growth does eventually start into a upper-bounded saw-tooth function. Given that the memory growth does seem bounded (although it seems to use far too much ram) – and I profiled NSD repeatedly with valgrind and saw no memory leak – I have been pursuing this as a potential memory fragmentation issue. However, looking at slabinfo while running my test harness, I am seeing multiple hundred times multipliers (400-500x from where it started) on the shared_policy_node and the anon_vma node after thousands of reloads.
I have data from this test harness (and the harness available if needed) for review. At this point, does anyone have any input on this?
Searched for it and found two leaks; those are in the zone name when a
file is read and in the radixtree when reading (larger) zones from
file and from zone transfer. The zonename is because the fileread
used to be in a separate executable, and the radixtree had a leak
because it allocated for type* and not for type, leaking the
difference (through our special purpose memory allocator).
My problem with reloading zones (mentioned here on Feb 17, 2014) is caused by a bug in the linux kernel concerning forking. NSD’s model of reloading really tickles this bug: https://lkml.org/lkml/2012/8/15/765
basically, forks take longer and longer and longer while slabs grow without bound until the inevitable.
Andreas: are you running linux?
I see no status on the patch mentioned in that thread, but we definitely have to periodically reload NSD until this issue is addressed.
Very interesting. We have the exact same issue, and our symptoms are
also the same. We periodically have to restart NSD to alleviate server
load. Wouter Wijngaards and I have been trying to find the problem for
ages, and we both thought it was in NSD. I've been trying various
patches he made, but nothing has helped, and now it seems clear why,
because the bug isn't in NSD. Of course, NSD's frequent forking probably
makes this worse, and on our server with several thousand zones, the
zone refresh rate is quite high.
yeah. I capture stats every minute as well – which profoundly aggravates the problem. Anything that forks – nsd-control [reconfig|reload|stats], etc will trip on this.
have you confirmed that you have an affected kernel? I can send you the test program we used to spot the issue, if you like…
yeah. I capture stats every minute as well -- which profoundly aggravates
the problem. Anything that forks -- nsd-control [reconfig|reload|stats],
etc will trip on this.
have you confirmed that you have an affected kernel? I can send you the
test program we used to spot the issue, if you like...
We're running on CentOS 6, with kernel 2.6.32, but with RedHat's patches
and backports, so it's not possible to say whether or not we have an
affected kernel.
However, I have seen the test program, and I am going to try it out to
confirm if we're affected by the same bug.
My problem with reloading zones (mentioned here on Feb 17, 2014) is caused
by a bug in the linux kernel concerning forking. NSD's model of reloading
really tickles this bug: https://lkml.org/lkml/2012/8/15/765
basically, forks take longer and longer and longer while slabs grow without
bound until the inevitable.
Andreas: are you running linux?
Will,
thanks for that information. I forgot that issue because I had some reboots
in the last months so the memory exhausting did not occur.
But: yes, I run linux: SLES 11, SP3
# uname -a
Linux dnsbl 3.0.101-0.15-default #1 SMP Wed Jan 22 15:49:03 UTC 2014 (5c01f4e) x86_64 x86_64 x86_64 GNU/Linux
Now I definitive know I have to restart NSD weekly...
My problem with reloading zones (mentioned here on Feb 17, 2014) is caused
by a bug in the linux kernel concerning forking. NSD's model of reloading
really tickles this bug: https://lkml.org/lkml/2012/8/15/765
We bugged SUSE support to get this fixed and received a special kernel
(3.0.101-0.40.1.7689.1.PTF-default). This is for SLES 11 SP3.
Folks with a SUSE support contract may open a ticket with SUSE to get it.
Also, it looks like an engineer at Yandex independently submitted a
fix in January which is now in Linux 3.19. As of this writing it's
only in mainline and not yet in the stable kernel: