Not to cache TXT records in general sounds sort of detrimental to the concept of a caching resolver. And apparently none of the resolvers does evaluate which TXT records are legitimate and which are useless/nefarious - as in being attempts of DNS tunnelling.
NULLs are used as placeholders in some experimental extensions of the DNS
As far as I have read and understood the best protection against DNS Tunnelling is traffic analysis, e.g. firewall with deep packet inspection, and/or tools for
payload analysis.
Interesting indeed but I am wondering whether there is a difference in the semantics of NULL records (rfc1035) and DNS query of type NULL (rfc8145).
One refers to a record and the other to a query type, with NULL overlapping and introducing a confusion, but albeit seeming to refer to different semantics?
And it seems unlikely that a Key Tag query could be utilized for any benefit in malicious DNS tunnelling.
I happened to hear from some DNS operators at some mobile carriers the other day who are scratching their heads about DNS tunnelling; they zero-rate DNS traffic for a variety of sensible reasons, but some of their more cunning customers have noticed that if they stop caring so much about performance, zero-rating DNS traffic can be turned into zero-rated mobile data.
It sounds like outlier identification (to find the unusually talkative mobile terminals) and rate-limiting (to make tunnelling painful without stamping too hard on DNS resolution) are the tools people have to work with. It might be nice if there were some convenient recipes for tuning unbound to do that kind of thing (from the perspective of the DNS operator/carrier, I guess, not the mobile terminal user).
Rate-limiting queries per source IP with specific query type (NULL/TXT) and long qname (e.g. 20 byte or longer). That should be possible using iptables hashlimit module and dns-extension [1].
That will make DNS-tunnel VPN useless while accepting legitimate TXT/NULL queries.
Thus I would reckon the OP has a valid point of questioning NULL records being cached by unbound, or even served to querying clients at all. There seems to be no mechanism however in unbound to prevent such.
I have read the following story about VPN tunnelling over port 53 at a mobile carrier but that is related to routing and I would trust that unbound is not the tool/place to control/analyse routing or be in charge of network traffic/package payload control, though bind features > rate-limit { responses-per-second ; } <
The carriers I was talking to were seeing IP tunnelled within
protocol-correct DNS queries and responses, including short, unique
QNAMEs, not just IP over 53/udp. The same technique would presumably
work just fine over DoH and other stub-resolver private channels
making the nameserver really the first opportunity to classify and
react to the traffic if it can be reasonably fingerprinted.
Resolverless DNS provides yet more potential opportunities to
exfiltrate routable packets, potentially behind a layer or two of
network defences around the HTTP/TLS termination machinery. Of course
you'd still need to find a DNS-later endpoint that was reachable
through any web namespace protections that evolve , etc.
Thanks for the elaboration. It would be cool indeed if the resolver would be able to detect anomalies in DNS traffic (and deploy counter measures) but suppose that is beyond the realm/scope of a resolver and left to tools dealing with packet/payload inspection/analyses, notwithstanding the DoH traffic you mentioned.
Anyway, seems a bit straying from what the OP been asking →
Thanks for the elaboration. It would be cool indeed if the resolver
would be able to detect anomalies in DNS traffic (and deploy counter
measures) but suppose that is beyond the realm/scope of a resolver ...
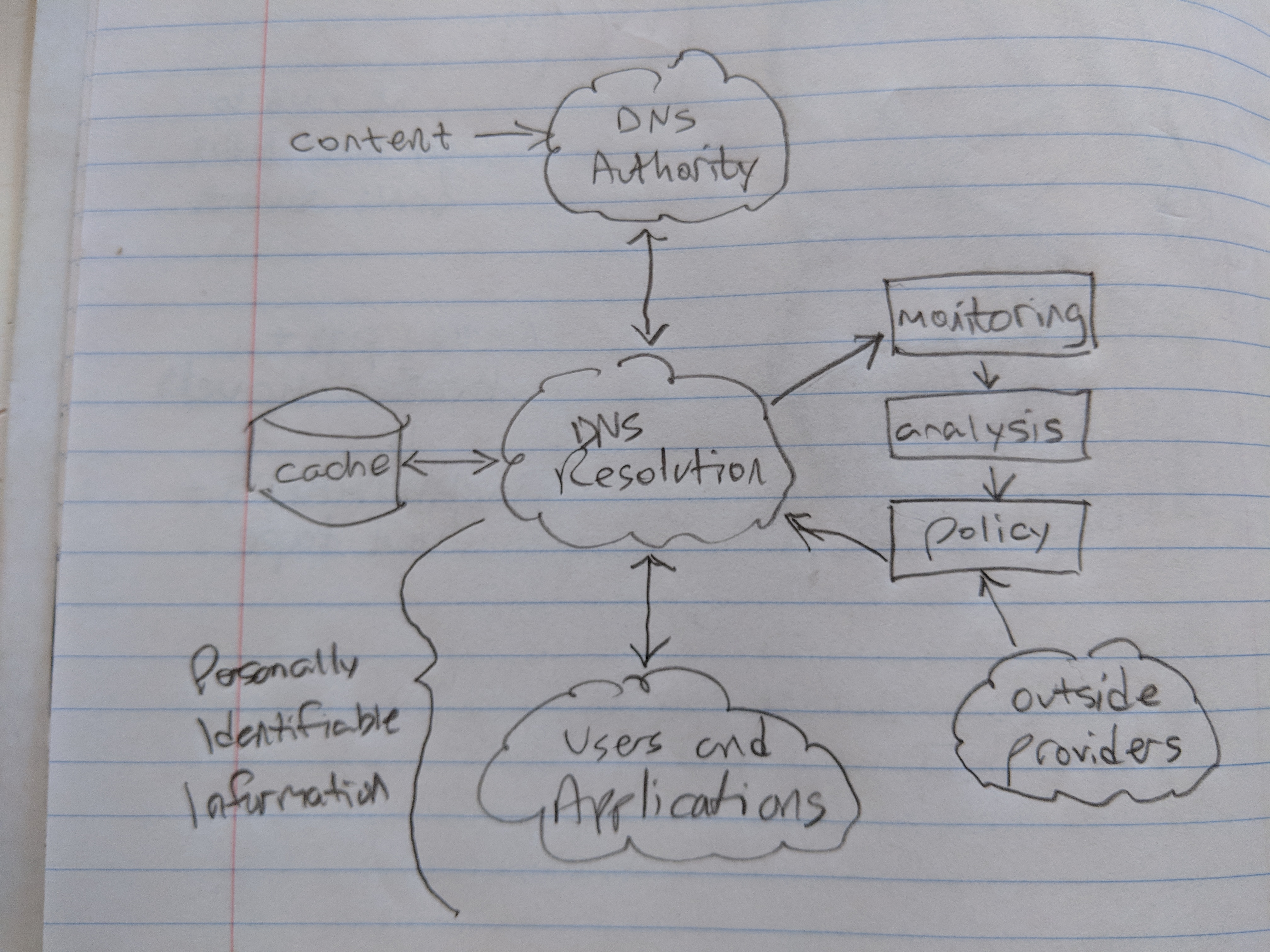
the caching recursive name server remains an excellent control point for network, user, and application security. however, instrumentation (something like 'dnstap') and control (something like DNS RPZ) are best externalized through standard API's (something like DNS RPS) so that the logic of detecting and controlling unwanted or dangerous DNS content or traffic can be competitive, transparent, and multi-vendor.
see the attached pencil diagram.
and left to tools dealing with packet/payload inspection/analyses,
notwithstanding the DoH traffic you mentioned.
DoH, by offering malware an over-the-top path to DNS content which can be neither filtered nor controlled by a network operator, will have to be widely blocked by enterprise and SoHo networks. this will sometimes take the form of whitelisting, other times blacklisting, often HTTPS MiTM, wider deployment of SOCKS, and more restricted BYOD policies. so, that game is beginning, but the old game is still going. neither the attackers nor the defenders will ever say, "ok ok, you've changed the rules, i guess i'll give up and do things your way now."
I will be preventing DoH on my networks/nodes for those reasons though likely DoH will find a receptive user/fan base (out of convenience and being promoted as saviour to DNS privacy/security).
But that aside, and not having contributed to the creation of the internet structure but ended up as a user that is impacted by using its facilities I am wondering more often whether certain parts need renovation or reinvention in some ways. I got only recently to appreciate the importance but also vulnerability of DNS. Suppose that during its inception the developers could not foresee all kind potential risks (malicious intent) and opted to keep things simple and liberal it though astonishes me that is even possible to run a SSH tunnel encapsulated in (obscured as) legitimate DNS traffic.
Well...I am not necessarily concerned by fact of DNS tunnel usage.
Users without permission for network traffic are successfully blocked.
Examples that i observe are rather experiments, not attempts of
stealing transfer (since they are allowed to make regular transfer).
What makes me worried: the transfer made through the tunnels is in
fact fully saved in cache... that's risky in terms of resources
(mainly memory). that's why forwarding TXT & NULL without saving
initially sounded like elegant solution for me.
Thanks for the elaboration. It would be cool indeed if the resolver would be able to detect anomalies in DNS traffic (and deploy counter measures)
Hi,
IP-ratelimit sounds good to me (as risk reduction Do you have some experience with values? Research needs to be done, in order to choose reasonable limit.
Filtering by qname lenght might be risky for legitimate traffic, i am afraid…
Whilst concurring on the abuse statement I am not sure why DNS tunnel users should actually be wary of caching. The caching related to the DNS tunnelling is bloating the cache, especially NULL records not serving any legitimate purpose in DNS. But to detect such users I would reckon that analytics are not looking at the resolver’s cache but rather the resolver’s log (dnstap)?
Fully agree. What is funny : tunnel “vendors” advertises it quite often as anonymization mechanism:-)
i think dns tunnels are an abuse of the service, and that users of dns tunnels should have a real and rational fear of caching.
i think those fears differ slightly. most RDNS servers do not log their transactions, though that's changing due to dnstap and analytics which can leverage dnstap. all RDNS servers have a cache which can be dumped. so, even though dns tunnels usually utilize the qname as a data carrier in the stub-to-authority direction and so the qname won't be predictable enough for others to query it, any RDNS operator who sees evidence of dns tunneling can dump her cache to analyze tunnel traffic in detail. that's a more-real fear simply because it is more common.
however, those concerns are in a way off topic for this mailing list, so allow me to ask a more direct unbound question. why does the cache bloat? you're using LRU replacement, and these records are never accessed. therefore while they can push other more vital things out of the cache, decreasing cache hit rate, they should be primary targets for replacement whenever other data is looking for a place to land. i understand that this cache churn has a cost, in bandwidth and in CPU, but not in memory -- once the cache reaches its working set maximum, it ought to grow no further. what could i be misunderstanding about this?
a second unbound-related topic is cache management itself. it is unusual for the splay between a name and its descendants to number in the millions. it happens for arpa, and popular TLD's such as COM, NET, ORG, and DE. as a cache management strategy, consider whether to more rapidly discard descendants of a high splay apex, unless they are accessed at least once. and in defiance my fear-related argument above, when the cache is full beyond some threshold like 90%, consider using the "splay is high, subsequent access of descendants is zero" as a signal to (a) not cache new descendant data, and (b) syslog it. there isn't a dnstap message-tag for this condition yet, but there ought to be. splay is easy to keep track of unless your cache is flat.
Rate limiting depends perhaps a lot on the user scenario, whether:
(1) the resolver is serving only trusted lan clients and in which case rate limiting may not be necessary unless suspecting a client being malicious.
Read a suggestion somewhere to establish a baseline for DNS queries from clients that represents the normal/average usage and set the rate limit in the firewall accordingly.
The firewall rate limit though is per packet and not per DNS query/response, which could be different due to payload - in particular if EDNS is added to the mix.
If EDNS is supported by both hosts in a DNS communication, then UDP payloads greater than 512 bytes can be used. EDNS is a feature that can be leveraged to improve bandwidth for DNS tunneling
(2) the resolver is serving untrusted wan clients and which case establishing a baseline and subsequent reasonable rate limit might prove difficult.
(Packet) rate limiting via firewall on its own would seem to be a rather rudimentary way of protection and some advance firewall logic/learning would advance the protection level, e.g. maximum amount of queries from the same client ip for the same TLD/SLD within the TTL.
BIND has implemented some Recursive Client Rate Limiting - https://kb.isc.org/docs/aa-01304, unfortunately Unbound appears not providing something of similar functionality.
however, those concerns are in a way off topic for this mailing list, so allow me to ask a more direct unbound question. why does the cache bloat? you’re using LRU replacement, and these records are never accessed. therefore while they can push other more vital things out of the cache, decreasing cache hit rate, they should be primary targets for replacement whenever other data is looking for a place to land. i understand that this cache churn has a cost, in bandwidth and in CPU, but not in memory – once the cache reaches its working set maximum, it ought to grow no further. what could i be misunderstanding about this?
Your understanding is correct I trust and bloating been a misdirection indeed. Referring to initial post: “Since I am observing a lot of DNS Tunnel “users” , the cache started to store totally useless records of type TXT and NULL.”
And in this context those queries, which to my understanding can be of high frequency in a DNS tunnel (depending on its purpose), are replacing legitimate records once the max. cache size is reached. And as you stated churning the cache comes at a cost. I am wondering what legitimate purpose it is for the resolver not only to cache NULL records but even serve them to clients other than perhaps some corporate edge/niche cases considering that at least rfc1035 does not specify a legitimate purpose for NULL records (as of today).
a second unbound-related topic is cache management itself. it is unusual for the splay between a name and its descendants to number in the millions. it happens for arpa, and popular TLD’s such as COM, NET, ORG, and DE. as a cache management strategy, consider whether to more rapidly discard descendants of a high splay apex, unless they are accessed at least once. and in defiance my fear-related argument above, when the cache is full beyond some threshold like 90%, consider using the “splay is high, subsequent access of descendants is zero” as a signal to (a) not cache new descendant data, and (b) syslog it. there isn’t a dnstap message-tag for this condition yet, but there ought to be. splay is easy to keep track of unless your cache is flat.
After reading it I thought that something like Rate-limiting Fetches Per Zone as implemented in BIND would be helpful to have in unbound too: “which defines the maximum number of simultaneous iterative queries to any one domain that the server will permit before blocking new queries for data in or beneath that zone.”