Hi,
We're running several unbound 1.6.0 (debian9 stable) instances for public service and we are experiencing service impactions while executing flush_zone action. As the instances have 32GB of memory and 4 skylake vCPUs, we beefed up the cache size parameters.
Current config, which leads up to overall of 22GB memory usage by the unbound process:
so-reuseport: yes
num-threads: 4
msg-cache-slabs: 4
rrset-cache-slabs: 4
infra-cache-slabs: 4
key-cache-slabs: 4
rrset-cache-size: 8000m
msg-cache-size: 4000m
neg-cache-size: 200m
key-cache-size: 500m
outgoing-range: 8192
num-queries-per-thread: 4096
so-rcvbuf: 8m
so-sndbuf: 8m
unwanted-reply-threshold: 10000000
infra-cache-numhosts: 500000
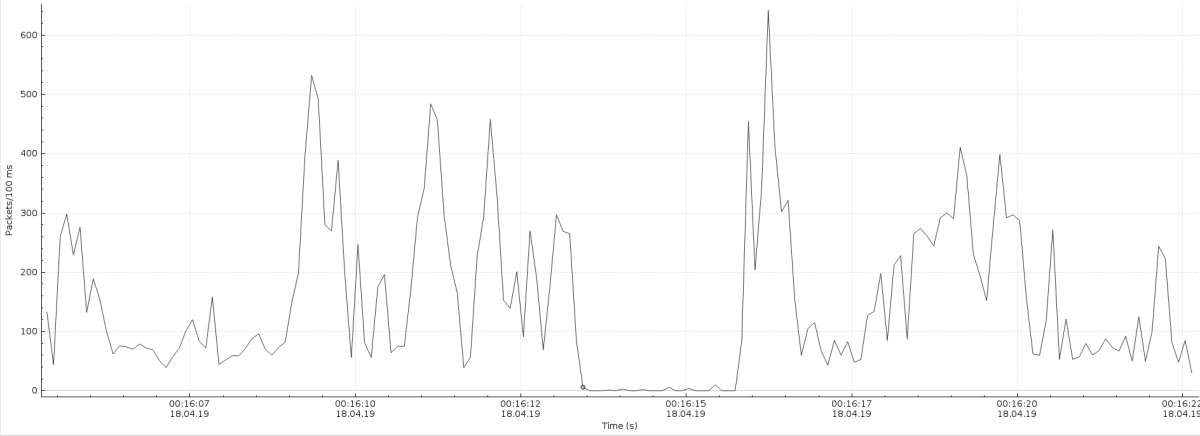
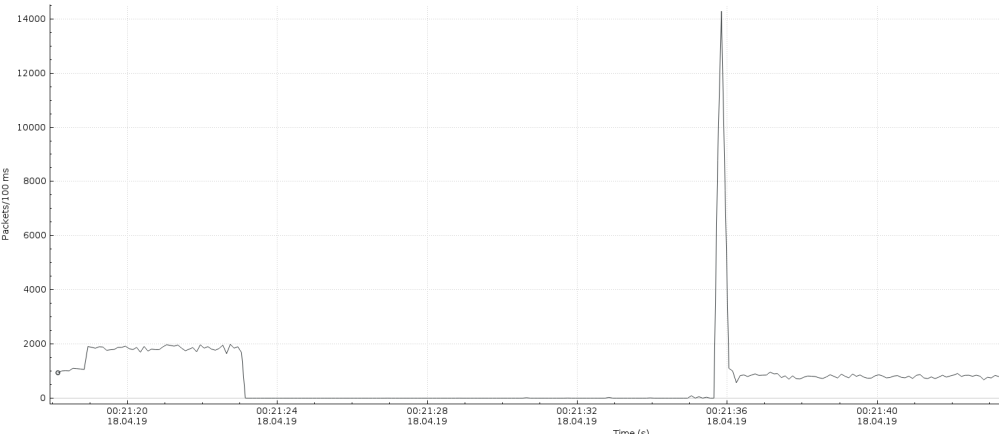
The 'unbound-control flush_zone some.domain' execution takes on busier instance 12..15 seconds. During flush, the unbound doesn't send out any DNS reply packets and there is silence on the wire until flush completes. The IO graphs in attach will demonstrate, how the source udp53 packet rate drops from 20Kpps to 0 for the flush execution time. Flush in a prime-time on a busy node easily results in a loss of approx 500K requests.
Unbound process consumes up all CPU resources (4vCPU's flat out), while in normal operation the CPU usage is avg 20..30%.
I gathered unbound-control status and stats outputs to separate file in attachment.
There is a massive burst of reply packets after the flush operation has been completed (see attached wireshark IO graphs). It could be related to kernel receive queue, which buffers queries while flush is in action.
Our main concern is the services unresponsiveness during flush. To reduce impaction time, we could decrease buffers size for example to following values, but it sure doesn't look like a solution to service impact.
rrset-cache-size: 640m
msg-cache-size: 320m
neg-cache-size: 32m
key-cache-size: 32m
Could there be any enhancements regarding cache handling and flush_zone in current 1.9 release compared to 1.6? In the changelog I couldn't find anything related to flush performance/impact.
Has anyone else had the same problem and could share some wisdom, how to get around it?
With larger cache size, theres also a bit more need for the flush to be usable.
kind regards,