Hi,
I've been testing Unbound 1.4.21's performance with the trafgen tool
from the netsniff-ng toolkit, with a stream of UDP queries for the same
qname/qtype in order to test Unbound's 100% cache hit rate performance,
and using Linux's traffic control facility to vary the query load
offered to the Unbound server. Then I use Linux's perf utility to
record performance data about the system under different query loads.
I read Unbound by NLnet Labs — Unbound 1.24.2 documentation and
configured the following settings in my Unbound config file:
num-threads: 4
so-rcvbuf: 8m
so-sndbuf: 8m
msg-cache-slabs: 8
rrset-cache-slabs: 8
infra-cache-slabs: 8
key-cache-slabs: 8
Under high loads but not under low loads, it appears the local_zone
lookup in worker_handle_request() is quite costly. Here are the top 10
profiled functions, with the top 2 function's call chains expanded:
- 7.22% unbound unbound [.] dname_lab_cmp
- dname_lab_cmp
- 78.04% local_zone_cmp
rbtree_find_less_equal
local_zones_lookup
worker_handle_request.part.19.13072.2480
comm_point_udp_callback.4353
event_base_loop
+ comm_base_dispatch
- 19.46% compress_tree_lookup.15131
packed_rrset_encode.15189
reply_info_encode.3179
reply_info_answer_encode
worker_handle_request.part.19.13072.2480
comm_point_udp_callback.4353
event_base_loop
+ comm_base_dispatch
+ 0.88% rbtree_find_less_equal
+ 0.53% packed_rrset_encode.15189
- 5.60% unbound libpthread-2.17.so [.] pthread_spin_lock
- pthread_spin_lock
- 53.14% worker_handle_request.part.19.13072.2480
comm_point_udp_callback.4353
event_base_loop
+ comm_base_dispatch
- 46.86% comm_point_udp_callback.4353
event_base_loop
+ comm_base_dispatch
+ 4.87% unbound [kernel.kallsyms] [k] _raw_spin_lock
+ 3.44% unbound [kernel.kallsyms] [k] _raw_spin_lock_bh
+ 3.35% unbound [kernel.kallsyms] [k] __ip_select_ident
+ 3.26% unbound [kernel.kallsyms] [k] fib_table_lookup
+ 3.12% unbound libpthread-2.17.so [.] pthread_rwlock_rdlock
+ 2.84% unbound [kernel.kallsyms] [k] fget_light
+ 2.80% unbound libpthread-2.17.so [.] pthread_rwlock_unlock
+ 2.78% unbound unbound [.] packed_rrset_encode.15189
I believe the calls to dname_lab_cmp() (#1) and pthread_spin_lock() (#2)
can ultimately be accounted to the call to local_zones_lookup() in
worker_handle_request().
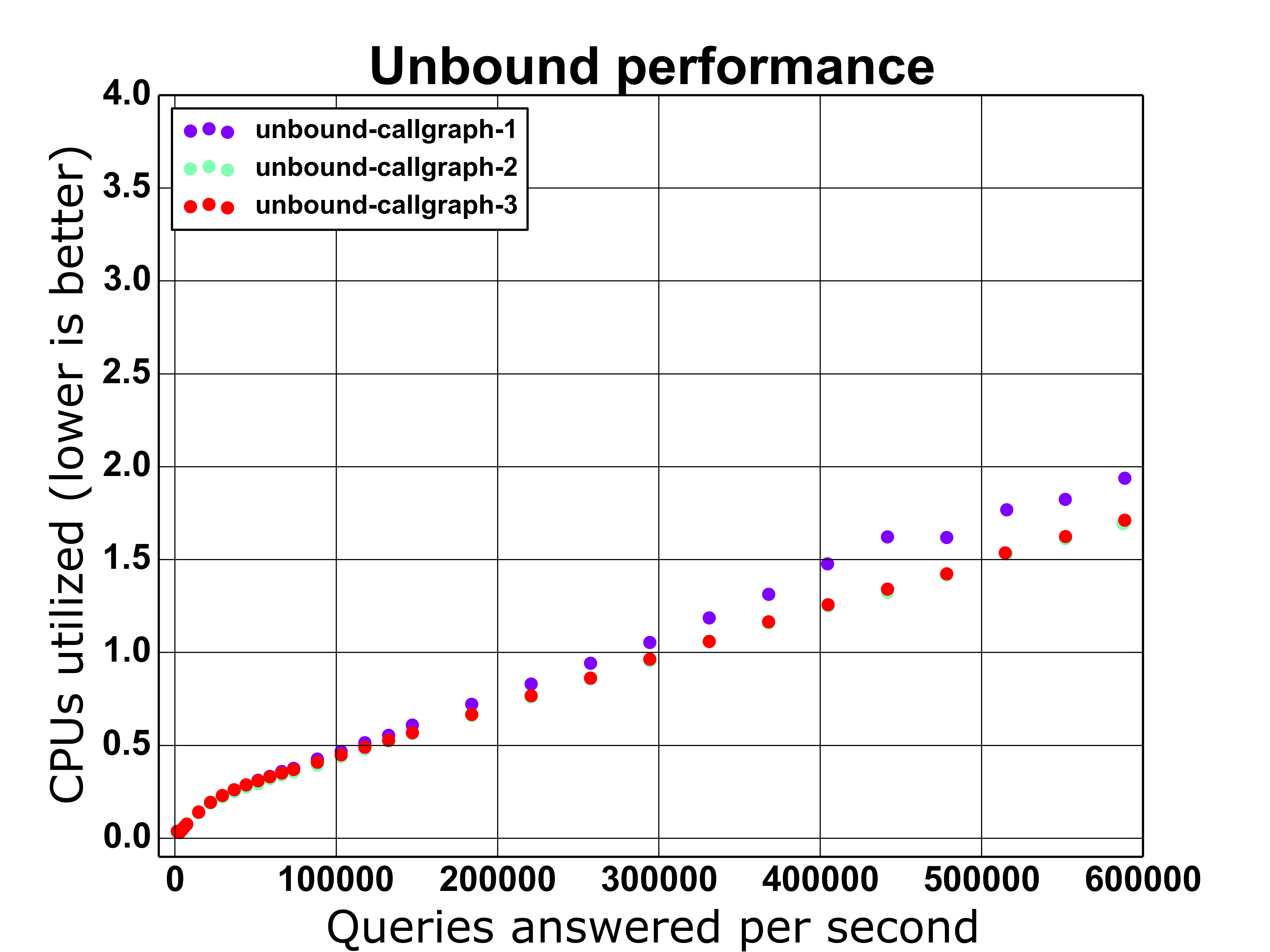
The benchmark run that the above data is from resulted in Unbound
utilizing 1.938 CPUs, according to the "perf stat" command. With the
following patch, disabling local_zone lookups entirely, Unbound only
utilized 1.693 CPUs.
diff -Npru unbound-1.4.21.callgraph/daemon/worker.c unbound-1.4.21.callgraph2/daemon/worker.c
--- unbound-1.4.21.callgraph/daemon/worker.c 2013-09-19 06:51:33.000000000 -0400
+++ unbound-1.4.21.callgraph2/daemon/worker.c 2013-12-27 17:53:29.589149356 -0500
@@ -862,6 +862,7 @@ worker_handle_request(struct comm_point*
server_stats_insrcode(&worker->stats, c->buffer);
return 1;
}
+ /*
if(local_zones_answer(worker->daemon->local_zones, &qinfo, &edns,
c->buffer, worker->scratchpad)) {
regional_free_all(worker->scratchpad);
@@ -872,6 +873,7 @@ worker_handle_request(struct comm_point*
server_stats_insrcode(&worker->stats, c->buffer);
return 1;
}
+ */
if(!(LDNS_RD_WIRE(ldns_buffer_begin(c->buffer))) &&
acl != acl_allow_snoop ) {
ldns_buffer_set_limit(c->buffer, LDNS_HEADER_SIZE);
Moving the local_zone lookup to occur after the cache lookup as in the
following patch, Unbound only utilized 1.712 CPUs.
diff -Npru unbound-1.4.21.callgraph/daemon/worker.c unbound-1.4.21.callgraph3/daemon/worker.c
--- unbound-1.4.21.callgraph/daemon/worker.c 2013-09-19 06:51:33.000000000 -0400
+++ unbound-1.4.21.callgraph3/daemon/worker.c 2013-12-27 18:32:01.916016428 -0500
@@ -862,16 +862,6 @@ worker_handle_request(struct comm_point*
server_stats_insrcode(&worker->stats, c->buffer);
return 1;
}
- if(local_zones_answer(worker->daemon->local_zones, &qinfo, &edns,
- c->buffer, worker->scratchpad)) {
- regional_free_all(worker->scratchpad);
- if(ldns_buffer_limit(c->buffer) == 0) {
- comm_point_drop_reply(repinfo);
- return 0;
- }
- server_stats_insrcode(&worker->stats, c->buffer);
- return 1;
- }
if(!(LDNS_RD_WIRE(ldns_buffer_begin(c->buffer))) &&
acl != acl_allow_snoop ) {
ldns_buffer_set_limit(c->buffer, LDNS_HEADER_SIZE);
@@ -924,6 +914,17 @@ worker_handle_request(struct comm_point*
ldns_buffer_rewind(c->buffer);
server_stats_querymiss(&worker->stats, worker);
+ if(local_zones_answer(worker->daemon->local_zones, &qinfo, &edns,
+ c->buffer, worker->scratchpad)) {
+ regional_free_all(worker->scratchpad);
+ if(ldns_buffer_limit(c->buffer) == 0) {
+ comm_point_drop_reply(repinfo);
+ return 0;
+ }
+ server_stats_insrcode(&worker->stats, c->buffer);
+ return 1;
+ }